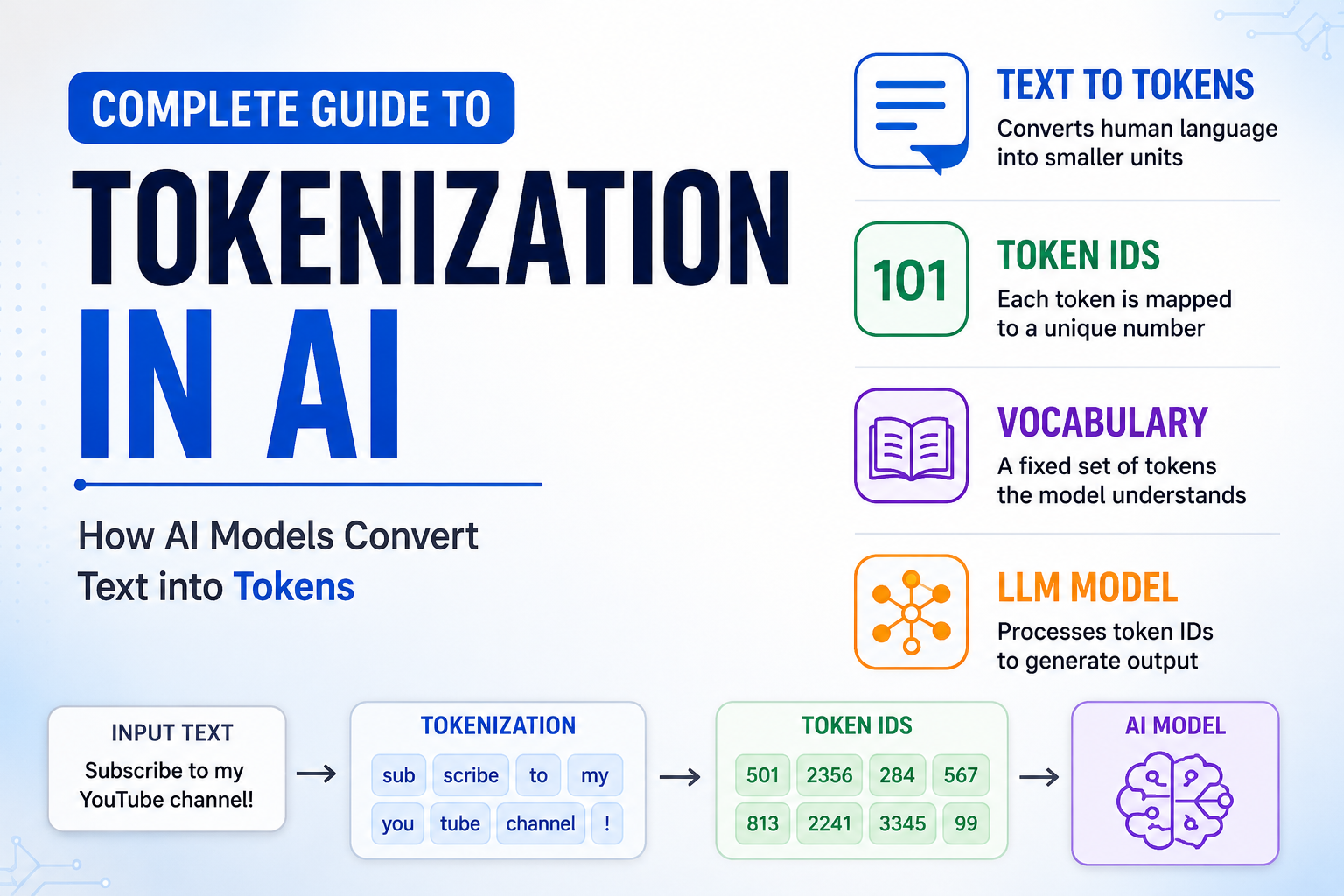
When we type a prompt into ChatGPT, Claude, or Gemini, the AI model does not actually understand words directly like humans do. Instead, every sentence is first converted into smaller units called tokens. The AI model takes input as tokens and returns output tokens. When you give one or more sentence to AI models then the first step is to convert those words/sentences into tokens which the AI can understand. In this complete guide, we will deeply understand how tokenization works internally in modern AI systems and large language models.
- What is Tokenization in AI?
- Why AI Models Need Tokenization
- What is Token ID’s in AI
- Why full words are not used as token in LLM
- Types of tokenisation
- How tokeniser decides word splitting
- How input prompt is converted to tokens
- Try some online tokenizers
- Why Developers Must Understand Tokens
- Python Code for LLM tokenisation
- Final Conclusion
- References
What is Tokenization in AI?
Tokenization is the process of breaking text into smaller machine-readable pieces called tokens. You take up a sentence which can have more than one word and then break those words into smaller sub words which are called tokens. For example let’s say there is a sentence
subscribe to my youtube channel codewithrajranjanWhen then tokenizer works then then it converts this sentence to
["sub", "scri", "be", "to", "my", "you", "tube", "chan", "nel", "code", "with", "raj", "ranjan"]This is not the only way in which the tokens can be formed. Each model has its own algorithm for doing the tokenization process and the output of the tokenization can be different for different models. Let’s not both on the actual process of tokenisation now, we will understand that in the later sections.
Why AI Models Need Tokenization
When we use to learn about the programming language then we use to learn that the computer understand the binary numbers (0,1). There is a compiler which converts that high level English language into the binary language.
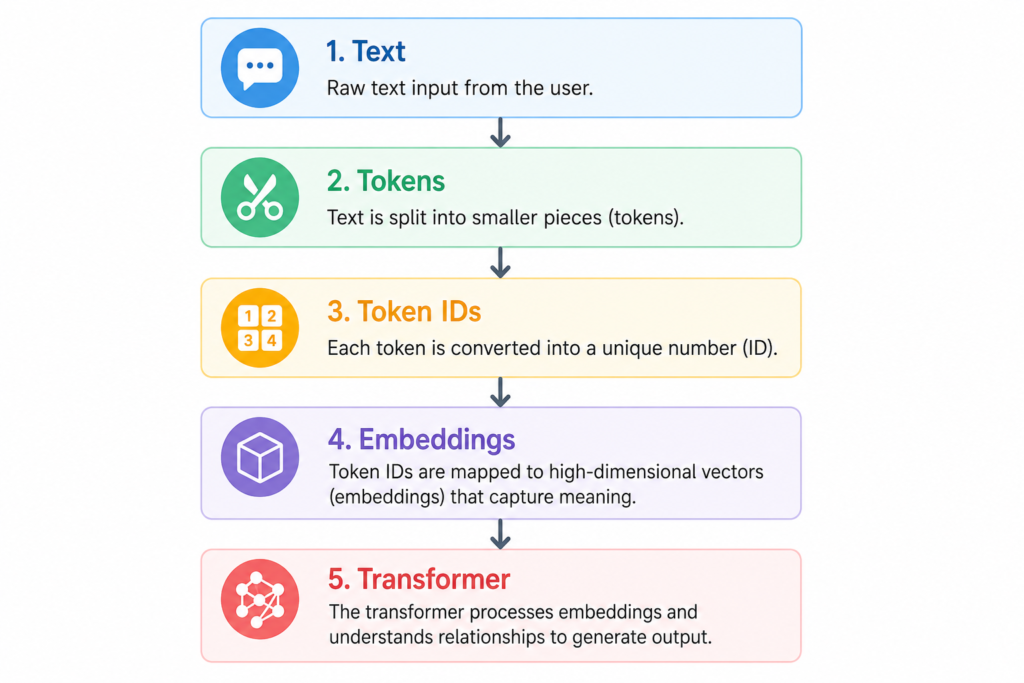
Same way the AI models understands token and not simple plain English so every model has a tokeniser component that converts the words/sentences into tokens. Tokenization is the pre-processing in the LLM lifecycle. The overall process in any AI model is represented below.
What is Token ID’s in AI
When the tokenization process happens then the first step is to break larger words into smaller strings or characters but if you see those small pieces then they are still English words which LLM don’t understands. Every LLM has its own token vocabulary which means all the tokens that the LLM model can understand.
Each token in the vocabulary is assigned a unique value like,50, 4534, 2323 etc. When tokenisation happens then the token must be present in the vocabulary such that we can assign a numeric value to each token. These numerical values assigned to the token is called the token id. AI internally processes numbers instead of text.
| Token | Token Ids |
| code | 44 |
| with | 5656 |
| raj | 345 |
| 4 | 234 |
Can Token Ids be duplicate
No tokens Ids will never be duplicate inside a tokeniser. Token Ids helps to unique identify tokens/words so needs to be unique. Same token can appear multiple times in sentence. For example
["code", "raj", "code", "raj"][665, 121, 665, 121]Why full words are not used as token in LLM
One thing always comes in mind that if humans think in words, then why don’t LLMs simply use complete words as tokens? At first glance, word-level tokenization sounds like the most natural solution. This approach appears simple and intuitive.
However, modern AI systems like ChatGPT, Gemini, Claude, and Llama generally avoid pure word-based tokenization because it creates massive practical and computational problems.
Human language is effectively infinite
- New words, slag, usernames, hashtags etc are constantly created
- For all of these the tokeniser needs to be constantly updated which is not feasible from the model training point of view.
Large number of Human language
There are so many languages like English, Arabic, Hindi, Japanese, emojis, code syntax etc. If we start storing all these things in the tokenised then the LLM vocabulary size will be very big. This will create the issue of vocabulary explosion.
The Unknown Word Problem (Out Of Vocabulary Problem)
If new words or hashtags are created then it may happen that during input processing the tokenizer has never seen a word before. If tokenizer only supports complete words then the model completely fails.
This is the reason we use subword tokenisation. Instead of storing all words the tokeniser store reusable subwords. for example
unbelievable["un", "believ", "able"]There are many advantages of using the subword tokenization
- Handle unknown words as the unknown words can be broken down into smaller subwords
- Small vocabulary of the Large Language model tokeniser. This makes retrieval of token ID fast
- The whole process of converting input and output token becomes efficient
Types of tokenisation
Character Tokenisation
The tokens are individual characters
codewitrajranjan["c","o","d","e","w","i","t","h","r","a","n","j","a","n"]Subword Tokenization
Then tokens are the subwords
codewitrajranjan["code", "with", "ra", "j ", "ran", "jan"]How tokeniser decides word splitting
You must be wondering that on what basis the tokeniser is diving the words into smaller subwords because you can do the subword creation process is many ways.
The tokeniser first learns the vocabulary from huge datasets during training. The tokeniser is trained on books, websites, GitHub code, wikipedia etc. There are certain learning process that it follows to Create the vocabulary like Byte Pair Encoding learning process
- Tokenizer starts with very small units usually characters or bytes
- Now tokenizer scans huge datasets and counts which adjacent pairs occur most frequently.
- Then tokenizer merges them and adds them to the vocabulary
- This process is repeated million of times.
- Tokenizer vocabulary is NOT manually designed. It is statistically learned from data.
- common patterns become tokens
- rare patterns usually are not considered as tokens.
Let’s say we take the word hyper initially it is converted into characters
h y p e rNow toekniser tries to scan huge datasets and counts which adjacent pairs occurs more frequently and creates then a token. Let’s say the hy occurs many times then it creates hy as a token.
How input prompt is converted to tokens
When the input prompt is given to the LLM model then the tokeniser must determine
- where to split the text
- which vocabulary tokens to choose
- how to do it efficiently
- how to avoid slow brute-force searching
Modern LLM tokeniser solve this problem using a combination of algorithms to covert the input large prompts into tokens in milliseconds using below algorithms
- Trie / Prefix Tree Lookup
- Greedy Longest-Match Algorithm
- Byte Pair Encoding (BPE)
- WordPieceSentencePiece
- Byte-Level Tokenization
Try some online tokenizers
There are some online tokenizer playground and you can play with them to see how the words/sentences are converted to tokens
Why Developers Must Understand Tokens
Tokens Directly Impact API Cost
Every LLM charge you based on the tokens sent and received. The more you spend the token the more cost you need to bear. If you are building AI Agents or AI related apps then you need to understand token better
Tokens Directly Affect Performance and Latency
More tokens mean the LLM needs to do more work at the computation level. Large prompt increase inference time, GPU workload, slower response generation.
Context Window Limitations
Every LLM has a maximum context window like 8K, 32K, 128K etc. This includes user input, system prompts, chat history etc
Python Code for LLM tokenisation
Let’s write a python code to convert a sentence into tokens and then token ids using different tokeniser
Install the dependencies
pip install transformersBasic Tokenization Using Hugging Face
from transformers import AutoTokenizer
# Load GPT-2 tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
text = "Subscribe to codewithrajranjan"
# Convert text into tokens
tokens = tokenizer.tokenize(text)
print("Tokens:")
print(tokens)- we have loaded the gpt2 tokeniser. you can load something different for trying
There can be possible output like this
Tokens:
["sub", "sc", "ribe","Ġto", .......]The special character Ġ represents a space before the word.
Convert Tokens into Token IDs
from transformers import AutoTokenizer
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
text = "What is tokenization in AI?"
# Convert text directly into token IDs
token_ids = tokenizer.encode(text)
print("Token IDs:")
print(token_ids)A possbile output can be
Token IDs:
[2061, 318, 11241, 1634, 287, 9552, 30]Convert Token IDs Back into Text
from transformers import AutoTokenizer
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# Example token IDs
token_ids = [2061, 318, 11241, 1634, 287, 9552, 30]
# Decode back into text
text = tokenizer.decode(token_ids)
print(text)Count Number of Tokens in a Prompt
This is extremely important for developers because:
- API cost depends on tokens
- context window depends on tokens
- latency depends on tokens
from transformers import AutoTokenizer
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
text = "Explain tokenization in large language models in detail"
# Encode text
encoded = tokenizer.encode(text)
# Count tokens
token_count = len(encoded)
print("Token Count:", token_count)Final Conclusion
In modern AI systems, tokenization is the process of converting human-readable text into reusable computational units. The typical flow is
Text -> Tokens -> Token IDs -> Embeddings -> Transformer -> Generated Output